The story of Ripped Records
Blog
Scraping unstructured music gig data, combining it with several free APIs, and making something beautiful
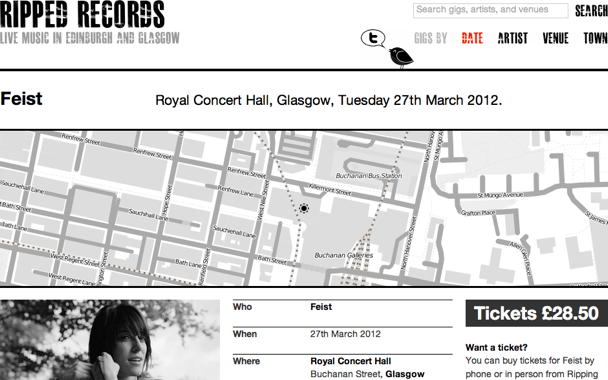
A screenshot of Feist’s artist page as it was on the Ripped Records website.
Ripped Records was a site that I ran for two years from February 2010 to March 2012. It’s special to me because it was the first real project where I used took ugly, barely parseable data and turned it into structured data.
What was it?
There’s a shop in the centre of Scotland’s capital, Edinburgh: Ripping Records. It’s an institution in the city and one of the last few physical connections to buying gig tickets. The shop has a big chalk board listing all the tickets they have on sale and you can chat to the staff, get recommendations, and so on. It’s fantastic.
But their website’s dreadful. I mean truly awful. It looks bad, it’s hard to use, and it’s almost impossible to discover what’s new. This is as true now in 2012 as it was back in 2009 when I took it upon myself to create something better.
My main aims were to make it easy to discover new tickets as soon as they were available, to give people visual clues as to what bands were where, and to allow people to browse by venue, band, and date — all things missing (then and still in early 2012) from the store’s own site.
There was no business model, there was no master plan, it was merely for the enjoyment found in creating something.
The technicalities
The site was written in Python and Django but the most interesting aspects of the project were the web APIs it used: Last.fm, MusicBrainz, CloudMade, the Guardian’s Open Platform, and — perhaps surprisingly — Google Docs.
Using Google Docs for data scraping
A long time ago I was noticed that there was a function in Google Spreadsheets called importHtml; it can import an entire table from an HTML page into a Google Docs spreadsheet, and have that spreadsheet update regularly. Google Docs allows spreadsheets to be downloaded as CSVs, and so I realised I could then download an HTML table as a CSV file with no programming or screen-scraping needed at all.
That intrigued me, so I thought I’d try and use it somehow. Ripped Records was the result. It was a lot of fun seeing that work so quickly and so smoothly. The only downside was that the information in the original table was so badly organised it took a lot of work to convert the CSV into information suitable for a normalised database. This was where I learnt the craft of cleaning up unstructured data.
By far the biggest problem with the data was misspellings. All the data on the Ripping Records site was — and still is in 2012 — entered by hand so band names, venues, and even towns were misspelled. A lot of the site’s code tried to handle that without needing my input.
The Guardian’s Open Platform
In late 2010 the Guardian got in touch with me and asked if I’d like early access to an API they were developing. It meant I’d be able to add the newspaper’s reviews of artists and live gigs, so I said yes. The API was fun to use and it was an interesting application of Linked Data. And of course it was nice to see my site featured on one of the Guardian’s blogs. Fame, however fleeting and minute.
The other APIs
Using the CloudMade API was fantastic fun. It’s like Google Maps only you can design the maps, which means the site has a more homogeneous feel rather than some ugly bright green and blue map sitting uncomfortably above everything else. When I shut the site down, CloudMade looked like it was starting to be superseded — in feature-set, mindshare, and usability — by MapBox, but I’m amazed I didn’t see it used more frequently over the last few years.
As for Last.fm and MusicBrainz, I didn’t use the APIs directly but rather used Python libraries to do the heavy lifting for me. That made it incredibly easy to do some quite interesting things — album art, artist biographies, and so on. That’s the beauty of APIs — and open-source — the sum is greater than the parts.
The end
The longer we go on the closer we come to death, and so it goes for Ripped Records, a site that fun was to create but never found the fame that would have given me enough reason to maintain and improve it. The site is no more — this page is the last remnant — and so with hosting fees saved I can head along to Ripping Records on Edinburgh’s South Bridge and have myself some of their tickets.
Update, 7th November 2016
After four decades, the Ripping Records shop closed its doors for the final time in November 2016. The website still lists upcoming events though.
Update, 10th August 2018
I recently rediscovered some long-lost screenshots of the different type of pages that populated the site. Here they are for perpetuity: